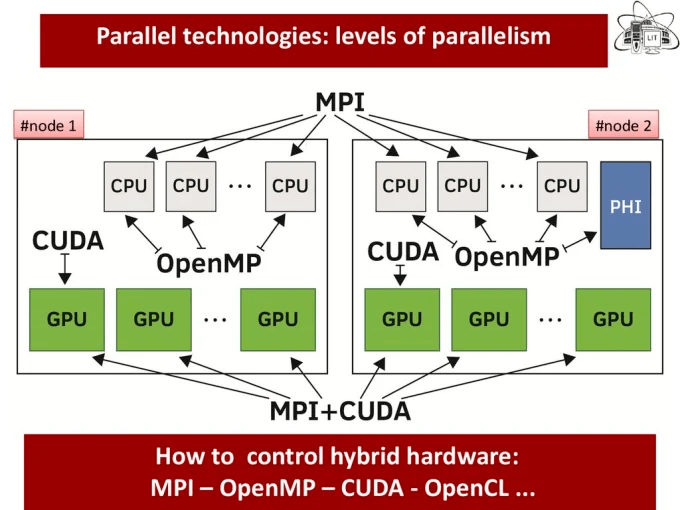
The HPC (high-performance computing) system combines the computational power of computer nodes to provide more combined power. It derives its computational power by exploiting parallelism using OpenMP, MPI, or hybrid MPI + OpenMP.
1) Why parallelism?
There are two main reasons to use parallelism :
- Computational time to solve a specific problem: achieved the same result in a shorter period, Solve a large problem simultaneously
- Problem size: solve a problem that cannot fit into a single computational unit’s memory.
2) OpenMP Vs MPI
OpenMP (Open Multi-processing) is a way to program on shared memory devices. Parallelism occurs when each parallel thread has access to all your data. It is designed for shared memory:
Pros
- A single system with multiple cores
- one thread/core sharing memory.
- Data shared is accessible by all threads in the team. Its accessibility is also faster due to the proximity of memory to the CPU.
- All threads access to the same address space.
Cons
- Cannot be scaled to a large number of cores
- Memory accesses are not uniform on modern CPUs
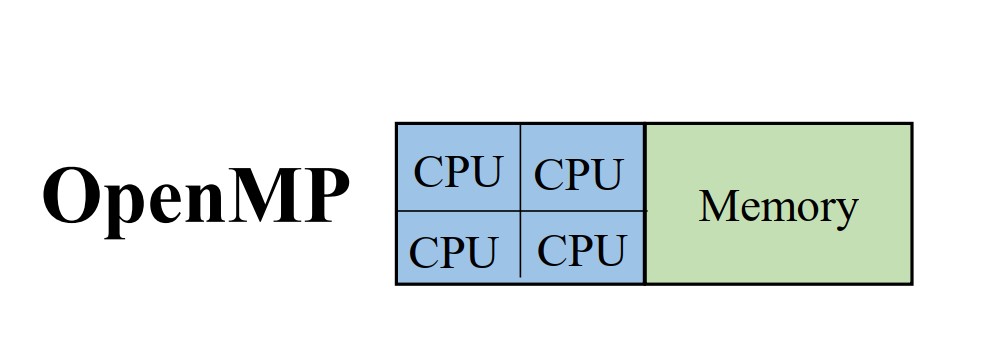
MPI ( Massage Passing Interface) is a way to program on distributive memory devices. Each parallel process works in a distinct memory space. It is designed for shared memory :
- Multiple systems
- Send/receive messages
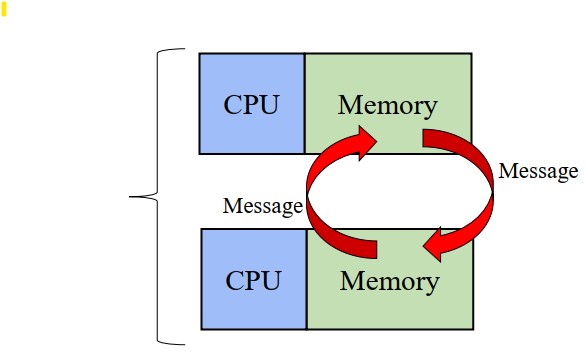
Pros
- Memory is scaled with the number of processors. Increase the number of processors and the memory size increase proportionally.
cons
- Data is scattered on separated address spaces.
- Data communication between processors is the responsibility of the programmer.
- Memory access times are not uniform – data on remote nodes takes longer to access than local data on a node.
3) Process vs Thread
– Program starts with a single process
– Process have their own (private) memory space
– A process can create one or more threads
4) OpenMP work-sharing constructs
Each member of the team will execute the enclosed code region individually, but it does not launch any new threads during its execution. A work-sharing construct does not have an implicit barrier to entry. Work-sharing constructs have a barrier at the end of the region. There are three types of constructions :
- Do/for-loop: shares iterations of a loop with the team. it represents the type of data parallelism.
- Sections: Breaks work into separate discrete sections. Each section is executed by a thread. It can be used to implement a type of functional parallelism.
- single: Serializes a section of code. Only one thread among the team thread will enter the code block. It also lets you specify that a section of code should be executed on a single thread, not necessarily the master thread. has an implicit barrier upon completion of the region, where all threads wait for synchronization.
5) Work schedule using for: How does lop get split up?
in MPI, we have to do it manually. But using OpenMP, we have two possibilities: Static or Dynamic scheduling.
In static scheduling: in this case, if you don’t tell the compiler what to do, it will decide by choosing the static chunk of the process. We can choose the size of chunks to take, keeps assigning chunks until done. Chunk size that isn’t a multiple of the loop will result in threads with uneven numbers.
Dynamic scheduling: Chunks are assigned on the fly as threads become available, when a thread finishes one chunk, it is assigned another.
If the loop iteration does not take the same amount of time, the load imbalance will happen. This will be explored more in detail in the coming publication on the performance of parallel computing.
6) What makes parallel programming more difficult than sequential programming?
There are many factors that make parallel programming difficult, amount them, we have:
- Finding and exploiting parallelism
- Finding and exploiting data locality
- Load balancing
- Coordination and synchronization of process
- Parallel performance
References
1- https://hpc-tutorials.llnl.gov/openmp/programming_model/
2- https://hpc.llnl.gov/documentation/tutorials/introduction-parallel-computing-tutorial##Models

I am a master’s student in Data Science and Scientific Computing.
Hello! I know this is somewhat off topic but I
was wondering if you knew where I could get a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having difficulty finding one?
Thanks a lot!