1. Problem statement
Italo Svevo, a pioneer of the psychological novel in Italy and one of the greatest Italian novelists, wrote and received letters in multiple languages during the twentieth century. The letters were recorded and stored in a database. Thus, the purpose of this project is to analyze those epistolary corpora to gain insight into topics and sentiments expressed (positive or negative) in his letters. This approach intends to extract information from the corpora by looking at the relationships between subjects, people, and emotions (fear, joy, sadness, anger), as well as how those interactions change over time.
2. Algorithms used to Approach the Problem
The number of topics discussed in letters will be determined using a Correspondance Analysis (CA). A visualization technique for identifying and displaying the relationship between categories. For the topic modeling, the Latent Dirichlet allocation (LDA) method will be applied for fitting the topic model. This is a stochastic algorithm that could have different results depending on where the algorithm starts, so we will need to specify a seed to ensure the reproducibility of results.
To find the emotion and sentiment expressed in each letter, the FEEL-IT (Emotion and Sentiment Classification for the Italian Language) model building in python release in 2021 [ref: 1] will be used.
3. Data description
The Svevo letter corpus dataset contains a total of 894 letters written by Italo Svevo including 826 letters written in Italian, 28 letters written in German, 30 in French, and 10 in English all written between 1885 and 1928. Data includes information about: the name of the corpus section, the index of the letter in the section, the date of the letter, the year of the letter, the sender of the letter, the sender’s location, the recipient’s location, languages used in the letter, the main language, and the text of the letter. There are 12 variables in total. Letters were mostly written in Italian with 816 sending by Ettore Schmitz, 30 by Eugenio Montale, 15 by Marieanne Crémieux Comnène, 11 by James Joyce, 8 by Benjamin Crémieux, 8 by Valerio Jahier, 5 by Valéry Larbaud, and 1 by Benjamin Larbaud to Svevo and his wife. We noticed an unbalanced distribution of data.
4. Experimental Procedure
For the experimental procedure, other corpora not writing in Italian were not considered since they did not contain enough letters to add meaningful information.
4.1 Data cleaning and Preprocessing
The following step was considered: remove all punctuation and numbers, lowercase the letters, delete the unnecessary white spaces and useless words ( u, essere, p, dopo etc), remove Italian stopwords and proper nouns, and the letters were then converted to DocumentTermMatrix which automatically apply tokenization.
4.2 Results and discussion
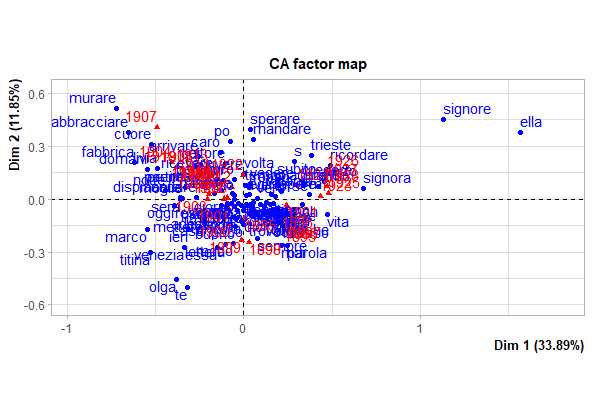
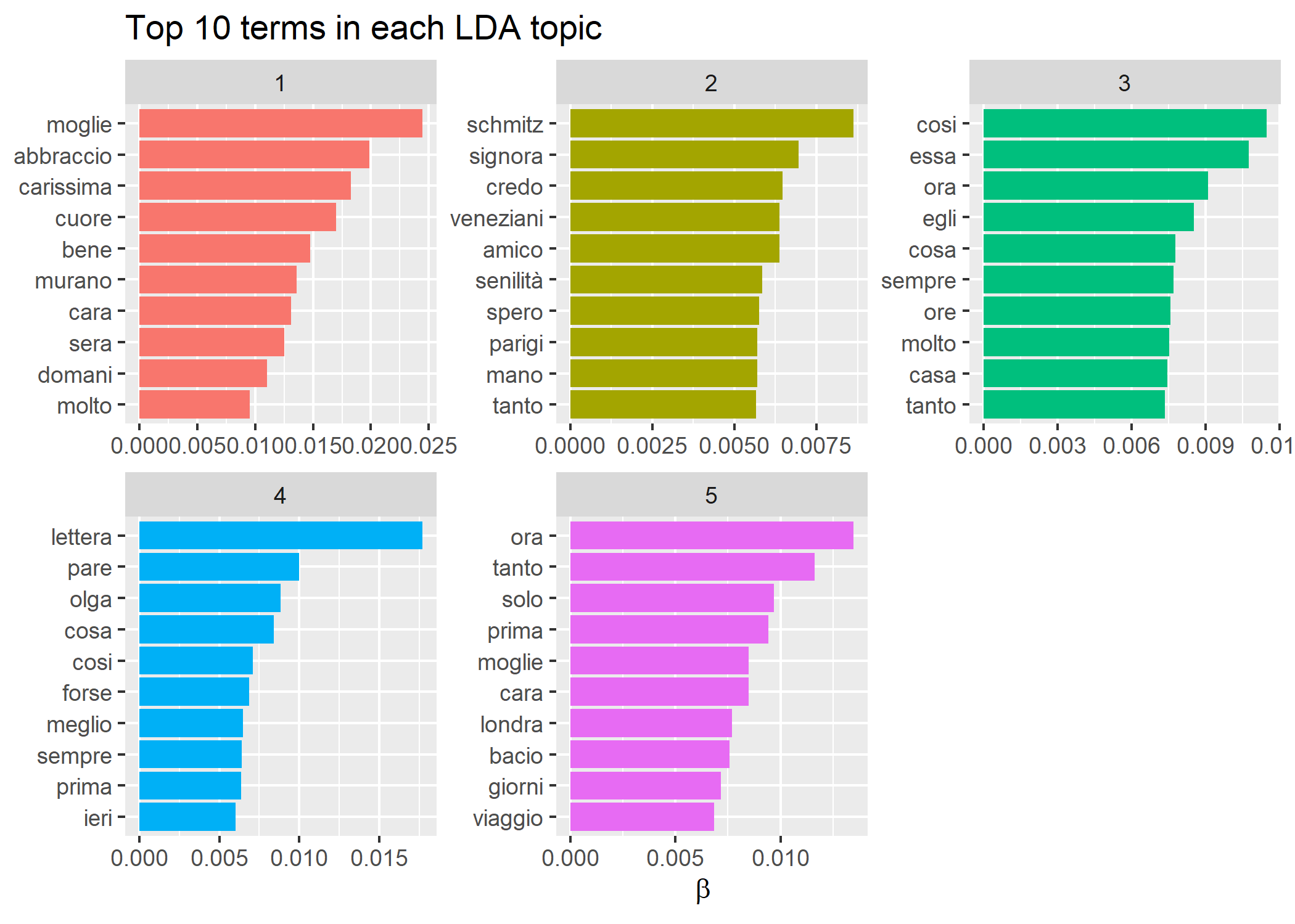
The Correspondence Analysis identifies the top five groups of topics that have been discussed in time (figure 1 a). This number was used to fit the LDA to identify the top words discussed in each topic ( figure 1 b) with $\beta$ (tf-idf) the probability of that term being generated from that topic. The topic modeling process has identified groupings of terms that we can understand as human readers and assigned to a group of discussion. The following topic was finally identified: Work (topic 1), Svevo Book(topic 2), Daily Life (topic 3), Opinion (topic 4), and Travel (Topic 5). By exploring the wordcloud figure 2, the following grouping of words and interpretations was found viaggo and londra refer to travel, affari and compagnia refer to Work, pareva, credo, and trovo refer to the opinion, bella,oggi, and adeso refer to daily life and scrivere and lettere refer to a book.

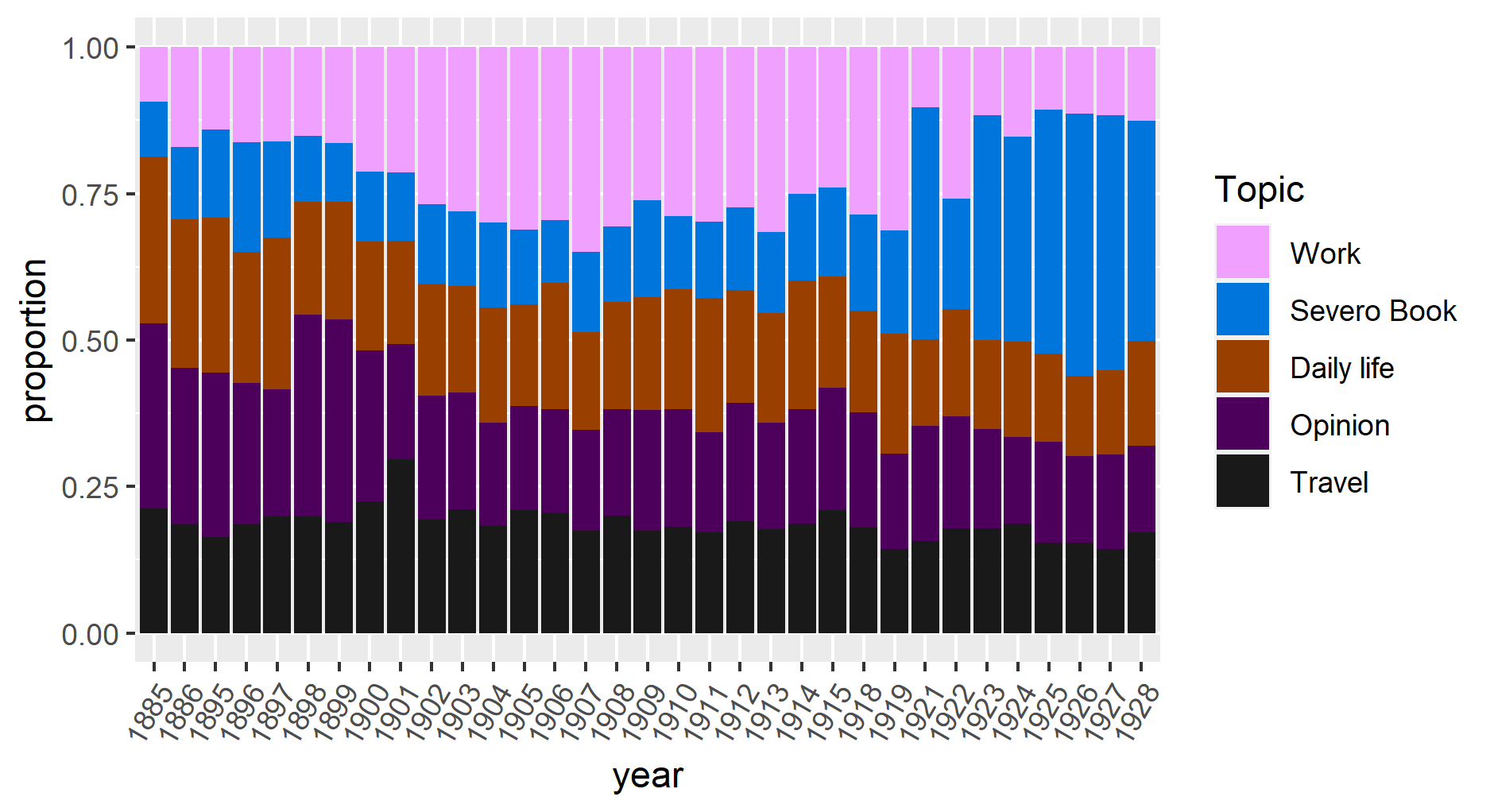
The study of the topic discussion proportions over years provides a distant view of the topic in the data. I aggregate mean topic proportions per year of all letters. These aggregated topic proportions can then be visualized in Figures 3 and 4. It shows that topics around the opinion, daily life, and travel dominate the first decades. Discussions around work were the most important topics in the second decade. Discussions around Svevo’s book have become increasingly important over the last decade. This can be interpreted as saying that books become more valuable over time. Based on the proportion of topics discussed by the sender, it becomes evident that most discussions around Svevo’s book were related to Eugenio Montale, James Joyce, Valerio Jahier, and Valery Larbaud, while Ettore Schmitz’s approximately discuss all topics with the same proportion.
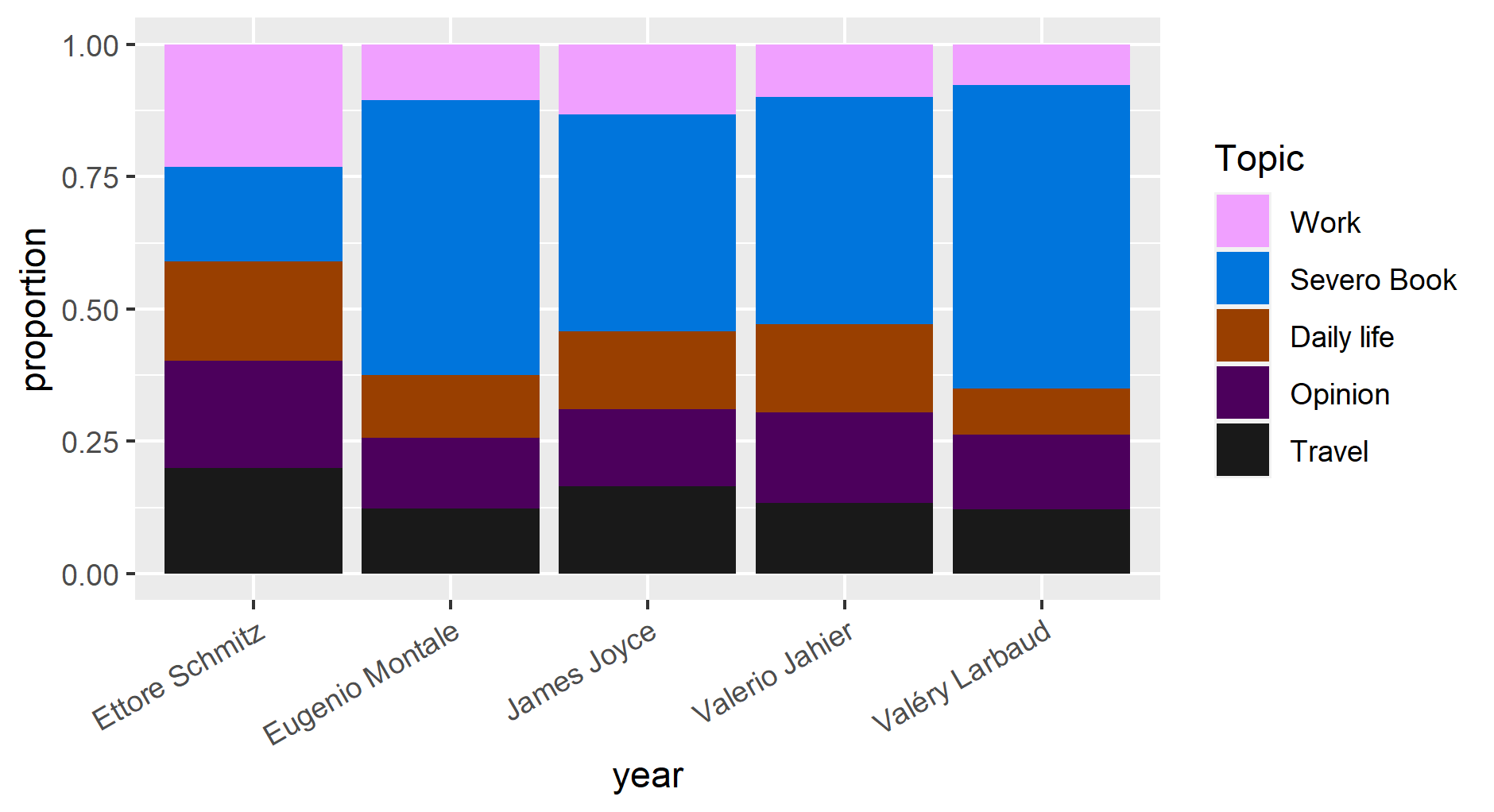
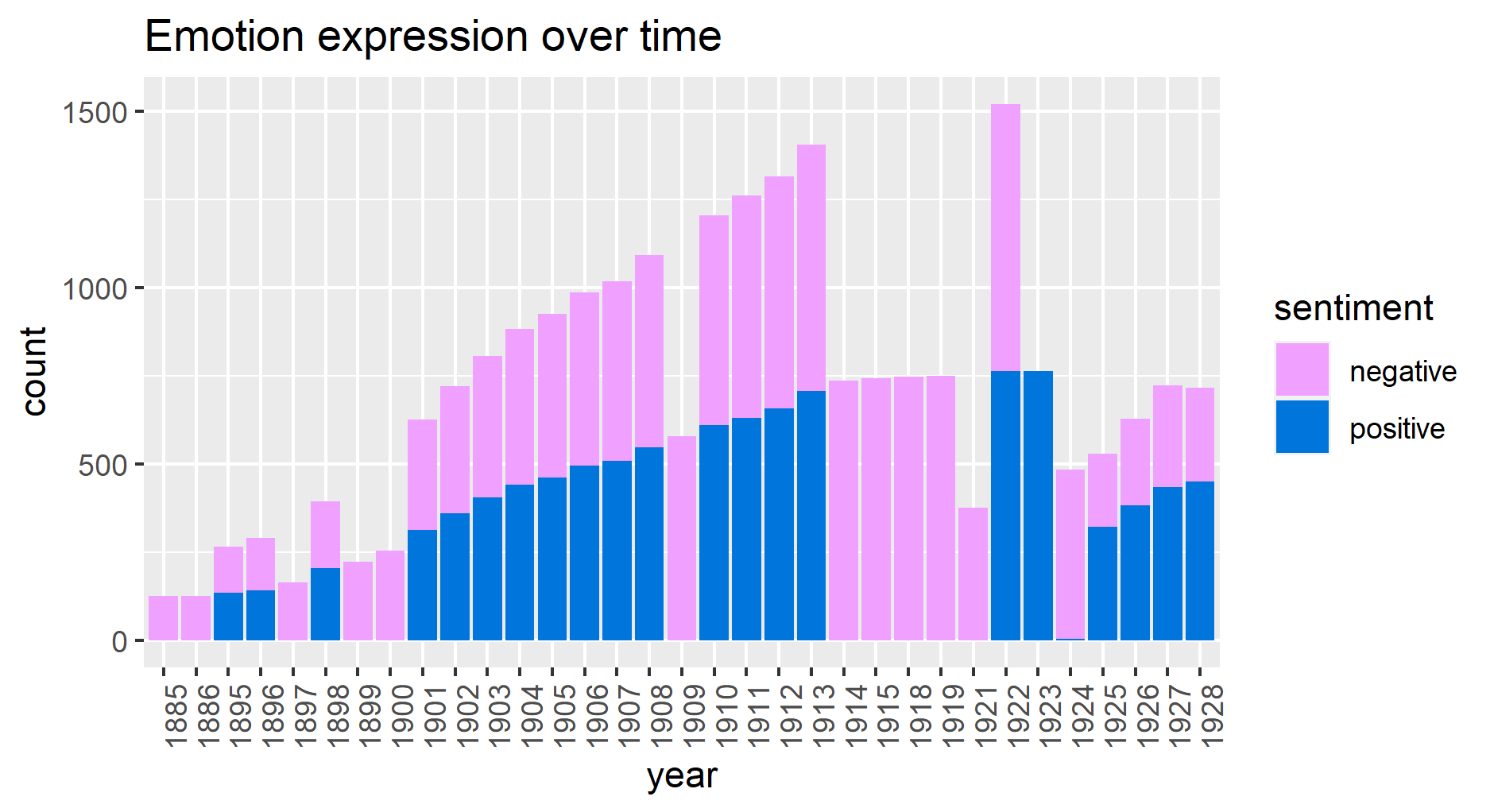
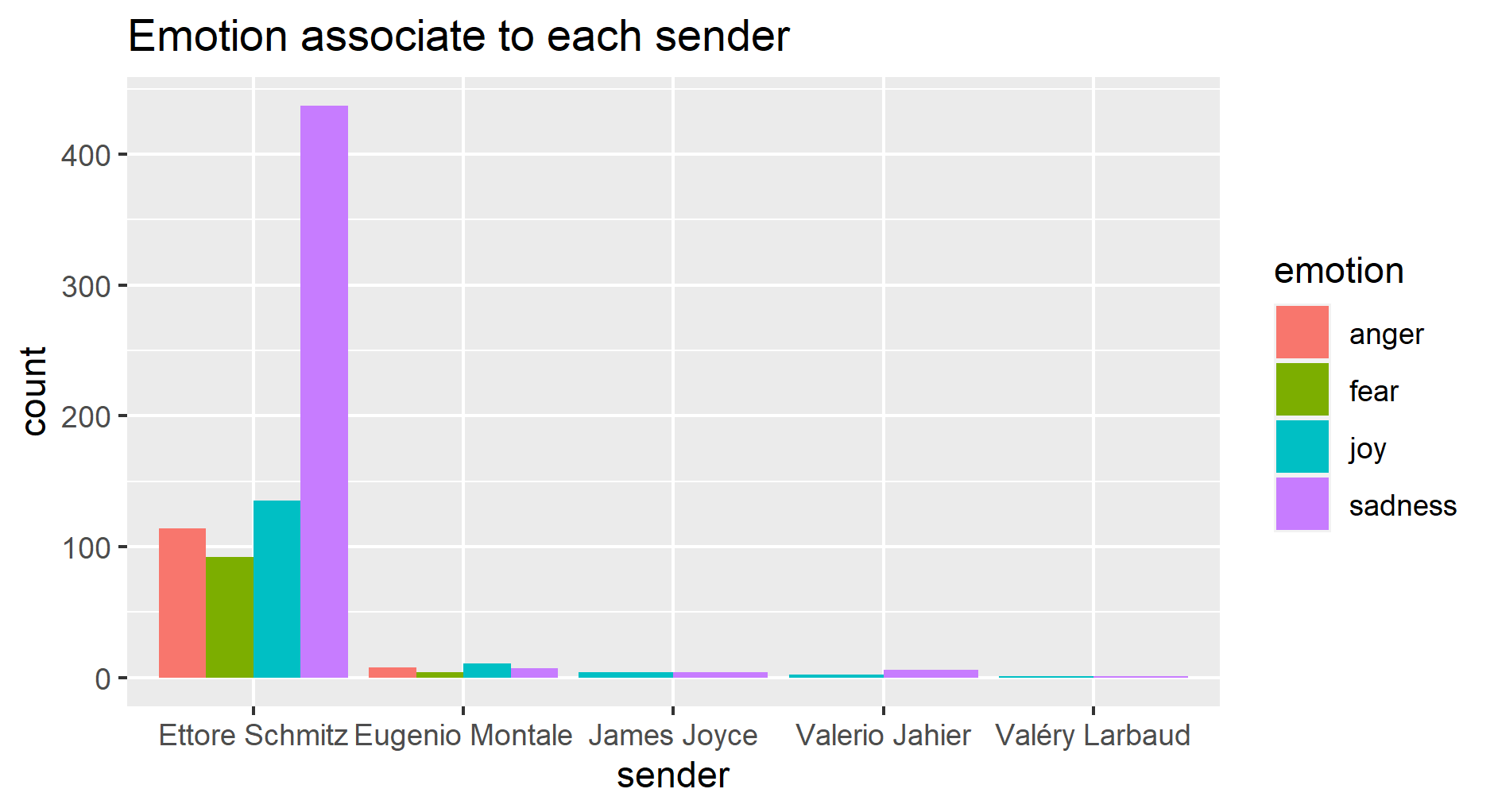
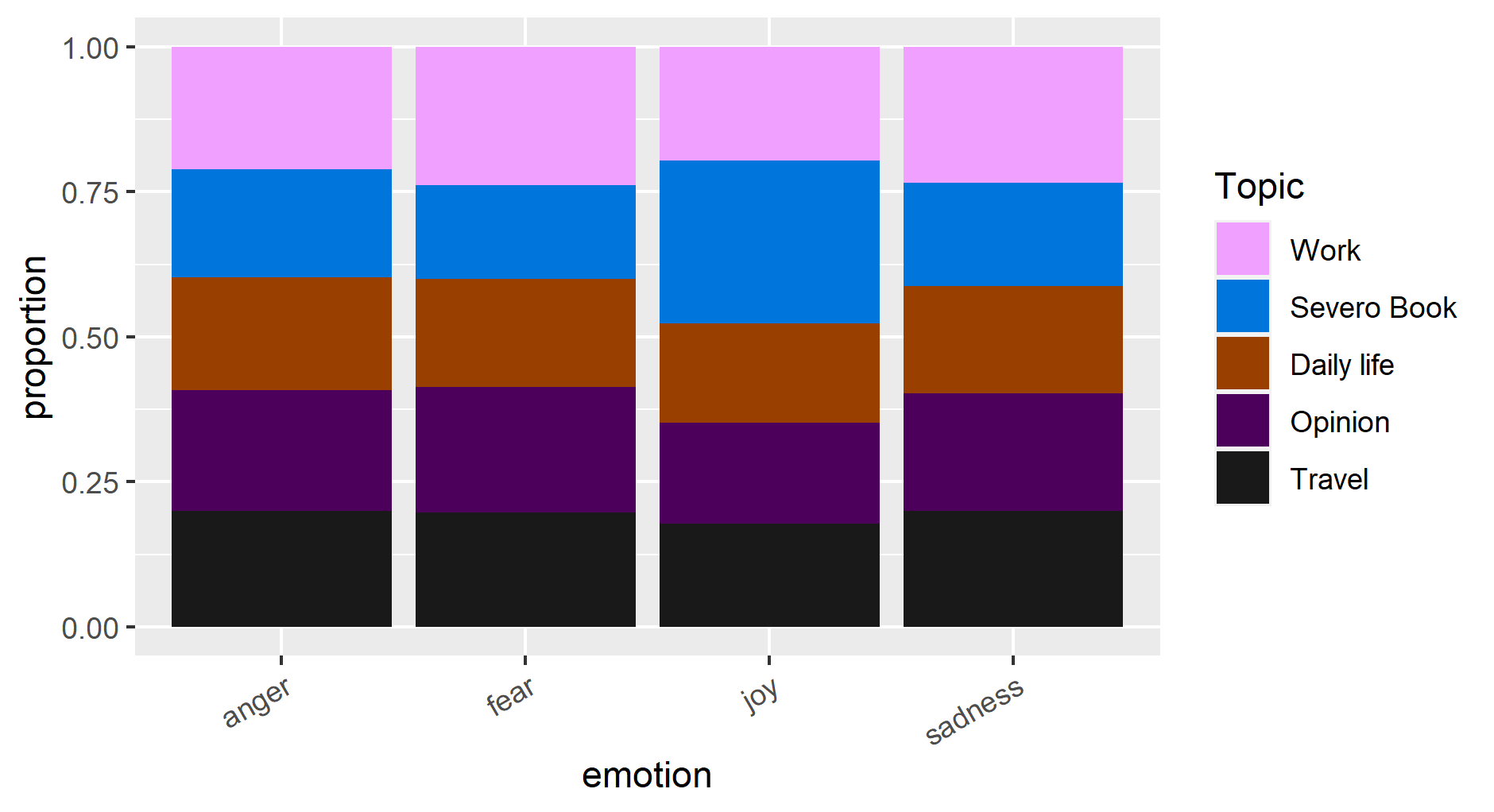
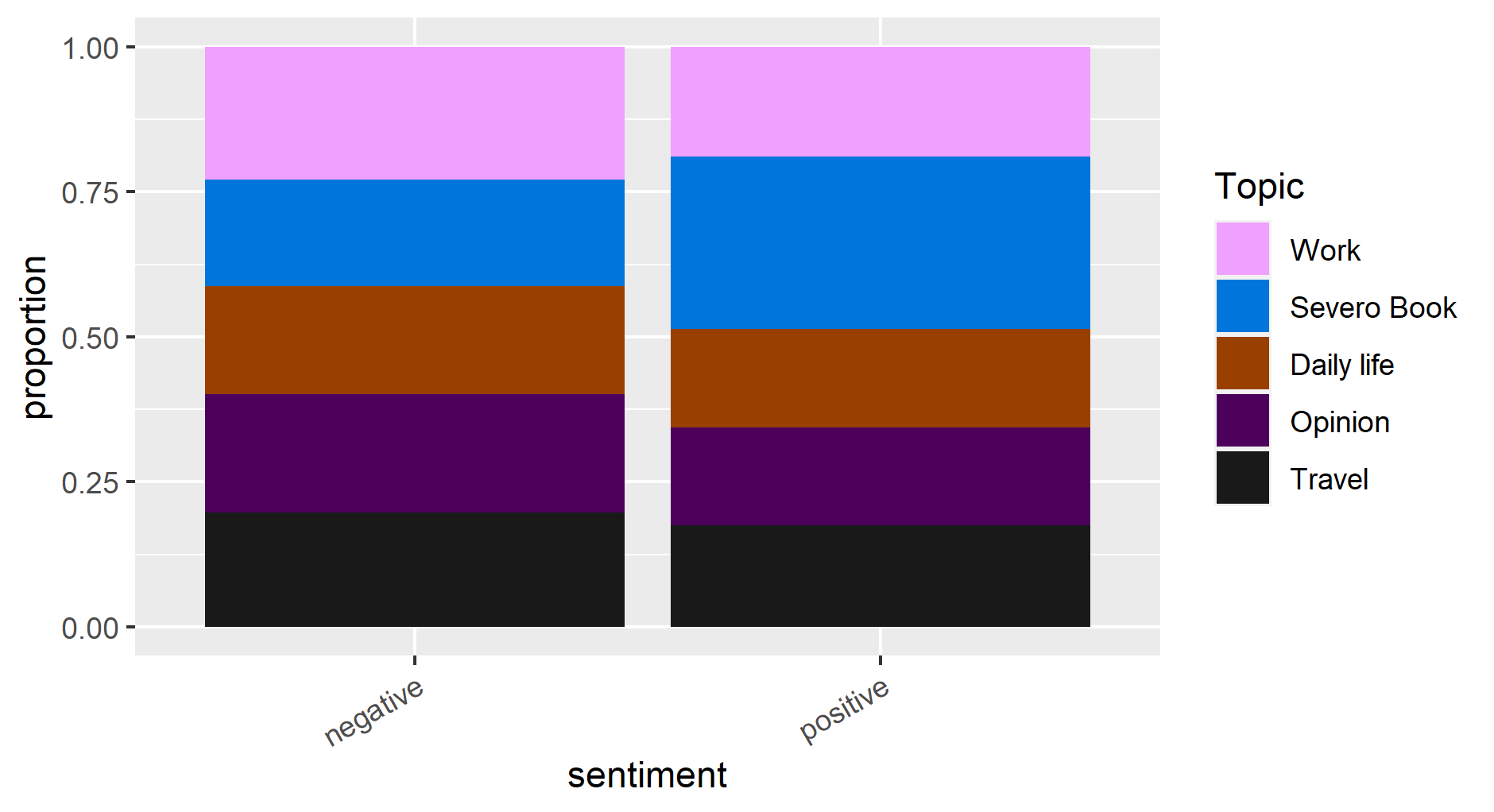
The analysis of emotion and sentiment using the FEEL-IT model helps to find the proportions of words related to them to have their trend profile over the year, see Figures 5 and 6. It shows the expressions of anger, joy, sadness, and fear linearly increase in the first 2 decades, but in the last decade, the sadness emotion almost disappears. The negative sentiment is dominant in the first two decades, but in the last decade, the positive sentiment becomes dominant. Figure 7 and 8 show that those emotion and sentiment are mostly connected to Ettore Schmitz who express more sadness and negativity. The data are unbalanced, this affects the interpretation of the letter sentiment and emotion over the decade. The analysis of emotion per topic shows that the discussion around Svevo’s book has a high proportion of joy and there is almost an equal amount of expression around other topics, it also has more positivity compared to other topic discussions (figure 9 and 10).


4.3 Github link for the code.
Reference:
[1] Federico Bianchi, Debora Nozza, and Dirk Hovy. ”FEEL-IT: Emotion and
Sentiment Classification for the Italian Language”. In Proceedings of the
11th Workshop on Computational Approaches to Subjectivity, Sentiment and
Social Media Analysis. Association for Computational Linguistics, 2021.

I am a master’s student in Data Science and Scientific Computing.